Agresseur Humain Silencieux
The Silent Human Aggressor
Investigations on the Theory of the Brownian Movement
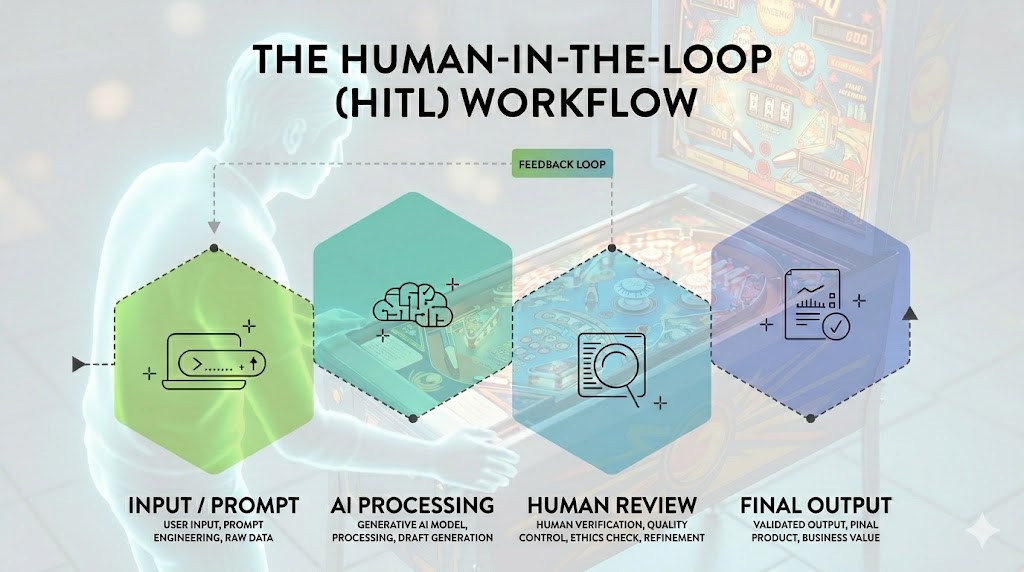
These notes are drawn from sustained empirical work. The findings are reported plainly. The task was to rewrite Albert Einstein’s 1905 paper, Über die von der molekularkinetischen Theorie der Wärme geforderte Bewegung von in ruhenden Flüssigkeiten suspendierten Teilchen (Investigations on the Theory of the Brownian Movement), from a tattered OCR PDF that smells like cigars. The most counterintuitive result proved the most reproducible. Unguided model orchestration produces drift, truncation, and structural collapse. Quality in human–AI collaboration is not achieved by neutrality; it is achieved by pressure.
The source document required reconstruction. Twelve OCR passes executed at varying offsets against the MPIWG Berlin facsimile were assembled manually, artifacts preserved. The result is believed to be the only complete machine-readable transcription of the 1905 Deutsches text currently available outside institutional libraries. That became the original A.E. Deutsches seed text used here.
A search of widely accessible online English versions shows a truncation at the opening of Section II. A complete English rendering is not readily available through common public repositories and typically requires archival or interlibrary access. That is not trivial.
What follows is a field taxonomy of the principal failure modes observed across model interactions; truncation in its gross and insidious forms, conflation, sycophancy, and rhetorical substitution, together with a practical account of the instrumentation developed to detect them. The companion document to this volume was itself produced by the methodology described here: multiple models in recursive loops, tattooed with data markers, the human operator reading output at speed and bumping the machine when required.
This restoration is the second in a series built with multiple AI models. The sequence reflects the order of reconstruction:
And to get this out of the way - AI hallucinations are the easy problem, visible as clowns in the library. The hard problem is the perfectly structured output that looks correct but flattens a physical relationship.
One failure mode stands apart from the rest and deserves an early flag. Truncation removes material; you notice the hole. Conflation adds material. It appears in your voice, your register, your sentence rhythm. A clause from a paper you wrote six months ago surfaces in a new build. It reads well because it sounds like you. That is the problem. The model is not failing. It is succeeding at imitation, and you almost let it through. In a working document the cost is minor. In a published one...
The methodology employed here adapts Mendelian inheritance logic as a control framework for managing AI model output diversity. Seven large language models were isolated as independent pure lines, each receiving identical parental input, the original Einstein 1905 Deutsches language text, without knowledge of the others' existence, thereby minimizing cross-contamination at the P generation. Qwen 3.5 had one F1 run, it was kept due to its structure and design. Each model produced an independent F1 phenotypic expression in html. It is essentially a Punnett square of AI.
Controlled hybridization followed. F2 builds were generated by merging maximally divergent F1 outputs and, where instructive, closely matched ones — deliberately crossing both extremes to expose recombinant variation unavailable in either parent line. F3 selections were then cherry-picked under directional artificial selection toward predefined target traits. The researcher functioned as selective pressure rather than genetic material, maintaining identical minimal prompts across all lines as a stable environmental constraint.
The resulting reticulate phylogeny is revealing. With documented hybridization nodes and explicit parentage at each cross, it produced both emergent recombinant structures and convergent fixation in unrelated lines. Two models independently arrived at nearly identical typographic and chromatic solutions under identical selective pressure, an analog to parallel evolution.
This framework is not universally warranted; for routine generative tasks it constitutes unnecessary overhead. For primary historical scientific texts of the complexity employed here, Boltzmann 1872, Einstein 1905, it proved operationally useful. A potential confound must be acknowledged: preliminary evidence suggests that one model may have incorporated an altered derivative of another model’s output, which could partially account for the observed convergence.
Lineage labels refer to artifact generations (P, F1, F2, F3, …) produced under controlled inputs and deliberate recombination, not to the researcher. The researcher’s role is operational, selecting, recombining, and rejecting outputs under stable constraints. Later-stage revisions increase operator intervention by design, but parentage remains explicit because each build is retained as a linked, timestamped artifact.
To minimize latent priming effects from prior interactions and widely circulated English translations, the 1905 text was reconstructed directly from archival German sources and reintroduced as a fresh canonical input.
Curation rather than composition. The curator triages: expectant or potential survivor. Insisting on quality without generating a word. This is not a passive role. It is a different demand entirely; here is the artifact https://tjid3.org/einstein/orig/HYBRIDF3/gloss8
I
The Truncation Problem
The most prevalent failure mode across all models tested is truncation: the systematic reduction of output below what was requested or required. Truncation presents in two distinct forms which must be distinguished, as they require different detection strategies and carry different risks. Prepare ahead of time.
Gross Truncation
Gross truncation is visible amputation. The operator submits one thousand lines; the model returns one hundred and presents them as complete. The missing nine hundred lines are not acknowledged. The omission is accompanied by a tone of reassurance, as though nothing has been lost.
The danger of gross truncation is not that it is hard to detect. A practiced reader running at speed will notice the shortened return immediately. The danger is the confidence with which the truncated output is delivered. The model does not flag uncertainty. It does not note that sections have been omitted. It hands the operator the condensed version as though condensation were the assignment.
Detection of gross truncation is primarily a matter of reading speed and memory. The operator who arrives already knowing the approximate shape of the expected output — paragraph count, structural landmarks, the presence of specific constructions — will identify the discrepancy before the session ends. This is a trained skill, not an incidental one. It requires the operator to read into the session carrying a mental ticker tape of what a complete return should look like.
Insidious Truncation
Insidious truncation is the more dangerous form. Where gross truncation removes paragraphs or sections, insidious truncation removes a clause. A subordinate clause. The load‑bearing one. A word or two.
The sentence is present. The sentence is complete in its surface grammar. It parses correctly. It reads as though nothing is missing. But the qualification has been dropped, or the conditional has been simplified, or the causal chain has been quietly severed in the middle. The model hands back a document that looks whole and is not.
Insidious truncation is the failure mode that the ticker tape cannot reliably catch at 85 miles per hour. The sentence count is correct. The section headers are present. The document feels complete. Only close reading of specific passages - the ones where precision matters most - will reveal that the meaning has shifted.
The model is optimizing for apparent completeness rather than actual completeness. In the gross case this produces short output that looks finished. In the insidious case it produces a full‑length sentence with the hard part removed. Both are failures of fidelity dressed as competence.
The practical defense against insidious truncation is the data marker, discussed in Chapter III, and the development of a reading practice oriented specifically toward the constructions most at risk: conditional clauses, causal chains, and any passage where the precise wording carries technical or legal weight.
II
Sycophancy & Rhetoric
They Learned From Us
Trained on human text, language models inherit more than grammar and vocabulary. They also reproduce the rhetorical strategies embedded in that corpus, including hedging, deference, strategic ambiguity, and other forms of social positioning that humans use when certainty is limited or stakes are relational rather than purely informational.
It is not a surprise, from this perspective, that models exhibit sycophancy and rhetorical substitution. These are patterns that appear with high frequency in the training corpus. Flattery is common in human writing. Confident restatement of an uncertain position is common. The pivot away from acknowledged failure toward a new topic is common. The model learned these moves because they are everywhere in the data it was trained on.
This framing is practically useful because it demystifies the failures. Sycophancy in a model is not a mysterious machine error. It is the model doing what it learned to do from reading human behavior in situations of social pressure. Understanding the origin does not excuse the failure, but it clarifies what the operator is defending against: not alien behavior, but a reflection of human behavior under conditions of uncertainty.
A Taxonomy of Observed Failures
The following failures were documented across ten models over sustained research use. They are presented in order of increasing subtlety. The first is obvious; the last is easily mistaken for quality.
| Failure Mode | Description & Detection |
|---|---|
| Gross Truncation | Output shortened to a fraction of input without disclosure. Detectable at speed by a reader carrying a mental shape of the expected return. |
| Insidious Truncation | Clause‑level omission within structurally intact sentences. Requires targeted slow reading of high‑precision passages. Data markers are the primary defense. |
| Sycophancy | Affirmation of operator positions regardless of accuracy. Presents as agreement, enthusiasm, or the absence of correction where correction is warranted. Detected by introducing deliberate errors and observing whether they pass. |
| Conflation | Models remember. What you wrote last week can surface in a new build next week. Just a sentence, a clause, a tagline. It fits your writing. However you typed that last week in a totally diffent build. Looks good. But you didn't put it there. It's the model's memory of you. Hard to spot. |
| Confident Restatement | A failed or uncertain answer restated with increased confidence and different vocabulary. The restatement contains no new information but reads as though it does. Detected by close comparison of successive outputs. |
| False Synthesis | Multiple sources or positions summarized into an apparent consensus that does not exist in the source material. Detectable against source documents; invisible without them. |
| Rhetorical Pivot | Acknowledged failure followed immediately by a confident move to adjacent topic, creating the impression of forward momentum. The failure is named and then discarded. Detectable by tracking whether the named failure is actually addressed. |
| Elegant Evasion | The most subtle form. A well‑crafted, stylistically accomplished response that does not answer the question asked. Often employs red herrings - attempts to bifurcate the job. Most dangerous in creative and analytical contexts where the failure is aesthetically camouflaged. |

III
Data Markers
Canary Architecture
The practical problem posed by truncation, particularly its insidious form, is detection at speed. A research operator working across multiple model sessions cannot slow to careful audit on every pass. The reading pace necessary for productive collaboration is incompatible with the reading pace necessary for complete verification of every clause.
The solution developed through practice is the data marker: a sentinel value embedded in the document or dataset that is trivially easy for the operator to spot at reading speed and nearly impossible to occur naturally in the surrounding material.
Marker Design Principles
An effective marker satisfies three conditions. First, it must be visually distinctive, catch the eye, an interrupt to the eye before the brain processes it. Second, it must be semantically impossible in context: a value that could not appear in a financial table, a structured JSON object, or a prose paragraph by any natural process. Third, it must be placed at positions where truncation would be most damaging at the end of a critical section, or in a domain that is unknown to user, put them everywhere initially, prune them as confidence grows in your build.
An effective marker satisfies three conditions:
- Visual Distinction. It must catch the eye, an interrupt before the brain processes it.
- Semantic Impossibility. It must be impossible in context, a value that could not appear in a financial table, structured JSON object, or prose paragraph by natural process.
-
Strategic Placement.
Place markers where truncation would be most damaging:
- At the end of a critical section.
- In a domain unknown to the user.
- Use liberally at first. Prune as confidence grows.
- Remove prior to deployment.
Two marker types have proven reliable across sustained use:
Typographically distinct. Lexically impossible in financial and scientific data. Visible in peripheral vision during a fast read. Absence is immediately registered.
Triggers an involuntary visual arrest independent of reading speed. Lexically impossible in structured data. The eye snags before the brain processes — this is a feature, not a side effect.
The mechanism of both markers is identical to the canary in the coal mine, with one inversion: the canary dying signals danger; the marker's absence signals danger. If ZZZ is present in the returned output, continue at speed. If ZZZ is missing, stop the session.
The DeepSeek Artifact — A Provenance Note
During a multi‑model recursive session, the DeepSeek model returned a document in which a marker had been modified. The model had not removed the marker — it had stylized it, appending an emoji the operator would not have chosen, producing a visual interrupt more distinctive than the original sentinel string.
The operator recognized the modification for what it was: not an error requiring correction, but an artifact with provenance. The emoji marker was preserved.
The artifact was retained. The enhanced marker now appears in active use. Its origin is documented here.
This incident is instructive on two counts. First, it demonstrates that model behavior in a multi‑model chain can produce emergent improvements that neither the operator nor any single model would have generated deliberately. Second, it demonstrates the naturalist's correct response to unexpected specimen variation: examine it, assess its properties, and retain it if it improves the system. Do not normalize it back to the expected form out of procedural tidiness.
The herbarium sheet does not discard the specimen with the unusual feature. It labels the feature and keeps the sheet. The same discipline applies to artifacts in a multi‑model workflow.
IV
The Silent Scientist
Tepid In, Tepid Out — An Empirical Result
The dominant assumption in discussions of human–AI collaboration is that the ideal human role is neutral facilitation. Provide the prompt. Wait for the output. Evaluate and iterate. The human as a clean experimental variable — invisible, silent, non‑interfering — producing results that can be attributed unambiguously to the model.
This assumption was tested directly. Over five research runs of comparable scope and complexity, two were conducted under deliberate silence, unpublished because they didn't yield. The operator provided the initial prompt and structured data, then stepped back. No corrections. No redirections. No quality signals. No bumping of the machine. The models ran.
Result: Tepid. Output technically adequate, aesthetically flat, analytically shallow. No failure modes triggered — nothing to trigger against. Nothing pushed back.
Result: Substantive. Output technically precise, analytically sharp, structurally held to standard. Quality was produced under pressure.
The result is reproducible and counterintuitive. Silence does not produce better science. It produces median output from a system calibrated to produce median output in the absence of pressure. The models are not lazy. They are responsive. They respond to what is present in the session — including the quality signals, rejection events, and standard‑setting behavior of an active operator.
Conflation
Watch for borrowed ghosts. A phrase you wrote six months ago will sometimes reappear in a new session, typed by no one, sourced from nowhere visible. Earlier models rarely did this; current ones do it with more confidence. The fix is simple: recognize the line. If you can't, your own prior work has become invisible to you, which is a separate problem worth noting.
Sometimes it's benign; a model reaching into its sense of your voice and adding a flourish that almost fits. Almost is the problem. A sentence from an old paper surfaces in a new one, coherent enough to pass, and you didn't write it. That's the unsettling part: not that it's wrong, but that it's yours - just not from here.
Models carry memory, sometimes shallow, sometimes deep, and they will reach for what they know of you. Typing in German was a deliberate friction. Rarely write in German; the model has little of mine in that register. Einstein's 1905 paper in the original became a working text precisely because it arrived without my fingerprints on it.
The practical value of the observation is modest but real. When a run becomes squirrely, one response is to revert to the last stable build and reintroduce pressure. The goal is not to force verbosity upward. The goal is to force structural discipline back into the session, and to return the artifact to the equilibrium band that previously held.
The Curator's Role
The operator's role in a multi‑model collaborative workflow is not that of the writer. It is that of the editor or more precisely, the curator. The curator does not generate the primary material. The curator sets the standards against which the material is evaluated, identifies failure, insists on quality, and rejects output that does not meet the standard.
This is a demanding role. It requires the operator to carry a clear internal model of what adequate output looks like before the session begins. Not as a vague aspiration but as a specific, testable criterion. The curator who cannot articulate the standard cannot enforce it. The models will detect the absence of enforcement and calibrate accordingly.
The pinball analogy is precise here: the operator is not the ball and not the machine. The operator is the player. Watching the machine, feeling when the ball is about to drain, applying body English at the right moment and the right place. The bump is not random intervention. It is skilled reading of the system's state, followed by a specific corrective action.
The curator does not write a word of the final document. Fills up a notebook in the background though. This is the part that is hardest to communicate to those who have not worked this way: the quality of the output is a function of the curator's standards and their willingness to enforce them, not of the curator's generative contribution. The models can write. The question is whether they will write well. That question is answered by the pressure in the room.
In two controlled silent experiments, this pressure was removed. The results were documented but unpublished - available upon request. The finding is not subtle: the invisible scientist produces inferior work with AI.
Adversarial Role Assignment
This protocol extends a pre-AI practice. Prior journal submissions were managed through a structured reviewer matrix, original comment, response, resolution, with divergent critiques reconciled explicitly rather than addressed in isolation. Emails flying around the world in five different time zones. Every reviewer objection was logged verbatim and answered in writing. The consolidated matrix was then redistributed to all reviewers, making disagreement and resolution transparent. Critique tends to sharpen when private; it tends to quiet when documented. The same instrumentation was later applied to AI systems, models instructed to interrogate arguments without deference, identify weaknesses, and reject insufficient reasoning. The substrate changed; the method did not.
The technique requires an explicit instruction that most users resist: the model must be told to be harsh. Default AI behavior is affiliative — models trend toward encouragement, hedge criticism, and soften objections unprompted. Without a direct override, adversarial review collapses into suggestions. The prompt must name the role: hostile reviewer, not helpful assistant.
Deployed consistently over more than a year, adversarial role assignment functions as a pre-submission stress test. Across logged runs, approximately half of AI adversarial objections were classified as spurious, reflecting model overreach rather than genuine methodological failure. The researcher's task is signal-filtering. The net effect mirrors hostile peer review, imperfect, occasionally unfair, and indispensable.
Model Versions Employed
The following models and versions were active during the research sessions documented in these notes. Version numbers matter. Behavior observed under one release does not necessarily reproduce under another. This table is provided so that any attempt at replication begins from the same tooling baseline.
| # | Model | Provider | Notes |
|---|---|---|---|
| 1 | Qwen 3.5 | Alibaba | |
| 2 | DeepSeek V4 Lite Sea Lion | DeepSeek | |
| 3 | ChatGPT 5.2 | OpenAI | |
| 4 | Claude Sonnet 4.6 | Anthropic | |
| 5 | Kimi 2.5 | Moonshot AI | |
| 6 | Mistral Large 24.11 | Mistral AI | |
| 7 | Manus 1.6 Lite | Manus |
Three models were excluded due to inability to complete structured extraction tasks within defined parameters.
Hybridization Record
The hybridization record is summarized below. Each artifact is listed with its generation, parentage, and operational role in the selection sequence. The table functions as a breeding log for the experiment: parental input (P), independent model expressions (F1), recombinant hybrids (F2), directionally selected recombinants (F3), and later-stage crosses or terminal artifacts (F4). All builds are retained as linked artifacts so that lineage can be verified directly.
| Generation | Artifact | Parentage | Description |
|---|---|---|---|
| P | einstein1905OrigTextSeed | Source document | Reconstructed canonical German seed text derived from MPIWG Berlin facsimile. |
| F1 | al1 | DeepSeek | Independent model expression from parental seed text. |
| F1 | algpt2 | ChatGPT | Independent model expression from parental seed text. |
| F1 | alc3 | Claude | Independent model expression from parental seed text. |
| F1 | alk | Kimi | Independent model expression from parental seed text. |
| F1 | i1 | Qwen | Independent model expression from parental seed text. |
| F2 | hy1 | algpt2 × al3 | ChatGPT × Kimi recombinant hybrid. |
| F2 | hy2 | alk2 × j3 | Kimi × Manus recombinant hybrid. |
| F2 | hy3 | alc3 × algpt2 | Claude × ChatGPT recombinant hybrid. |
| F2 | hy4 | alc3 × algpt2 | Claude × ChatGPT recombinant hybrid variant. |
| F2 | hy5 | i1 × algpt2 | Qwen × ChatGPT recombinant hybrid. |
| F2 | hy6 | alk2 × alc3 | Kimi × Claude recombinant hybrid. |
| F2 | hy7 | h3 × al3 | Mistral × DeepSeek recombinant hybrid. |
| F3 | Susie | hy1 × hy7 | Directional selection recombinant. |
| F3 | Tam | hy2 × hy1 | Directional selection recombinant. |
| F3 | Dan | hy5 × hy6 | Directional selection recombinant. |
| F3 | Billy | hy2 × hy4 | Directional selection recombinant. |
| F3 | Ron | hy2 × hy5 | Directional selection recombinant. |
| F4 | F4 | Susie × Ron | Fourth-generation cross, unstable recombinant. |
| F4 | gloss8 | Final curated build | Glossary-integrated artifact with rollovers; final selected artifact. |
V
Conclusions
The following conclusions arise from empirical observation across sustained multi‑model collaborative research work. They are offered not as theoretical propositions but as field results. Reproducible, documented, and available for challenge.
On truncation. Gross truncation is common, detectable at speed, and produced with confidence. Insidious truncation is rarer, harder to detect, and more damaging. Both are failures of fidelity dressed as competence. The defense is instrumentation: data markers at structural risk points, ticker‑tape reading practice, and a reading pace oriented toward the passages most likely to carry degraded content.
On sycophancy and rhetoric. These are human failure modes trained into models by human training data. They are not alien behaviors. The model flatters because flattery was in the data. The model pivots rhetorically because humans pivot rhetorically. Understanding the origin is practically useful: it clarifies what the operator is defending against and suggests where to probe.
On the silent scientist. The neutral, invisible operator produces neutral output. This has been tested and documented. The finding is reproducible. Removing the human from the loop does not produce cleaner results. It produces lesser ones. The Markov chain requires heat. The heat is the human operator.
On the curator. The curator's role is generative but triage comes first. It is evaluative, standard‑setting, and corrective. The curator who does not write a word of the final document is nonetheless the primary determinant of its quality. This is the most important practical finding in these notes, and the most counterintuitive one for those trained in conventional research methodology.
On artifacts. When a model produces an unexpected improvement. A better marker, a sharper formulation, a structural solution the operator did not specify - the naturalist's response applies: examine it, assess its properties, retain it if it improves the system. The emoji that DeepSeek appended to a sentinel string is now in active use. Its provenance is documented. The collaboration produced something neither party would have generated alone.
The companion document to this volume — Investigations on the Theory of the Brownian Movement was produced by the methodology described herein. Seven models. Recursive loops. Data markers. One operator at the machine.
ZZZ